What is the need for Terraform State? #
- Understanding Need for Tracking Infrastructure Changes: Without tracking, Terraform wouldn't know what resources were created earlier - If you run
terraform apply, it might recreate resources again! - What is Terraform State: A snapshot of the real-world infrastructure Terraform manages, stored in a file (
terraform.tfstate)- Stores Metadata and Resource Attributes: Includes resource details - IDs, names, IPs, and other details
- Needed to Safely Plan, Update, and Destroy Infrastructure: Helps Terraform make accurate decisions during
planandapplyoperations - Enables Accurate Change Detection: Compares your
.tfconfiguration with the current state to show only what's changed - Critical for Drift Detection: Helps Terraform identify when real-world infrastructure has been changed outside Terraform (Drift - A resource created by terraform is changed manually directly in the cloud platform)
- Key Terraform Commands: That Might Modify Terraform State
terraform apply: Creates, updates, or deletes infrastructure and updates the state fileterraform destroy: Deletes all managed resources and removes them from the state fileterraform refresh: Fetches real-world resource values and updates the state file without changing infrastructure
What are Desired, Known and Actual States? #
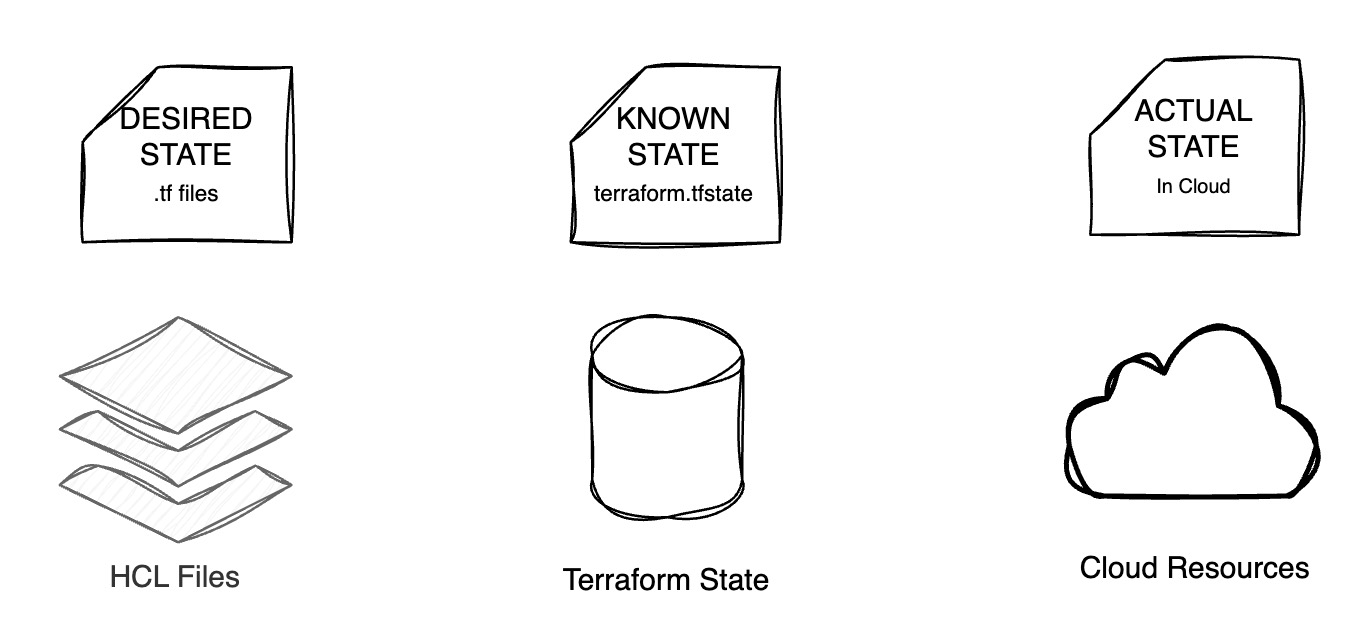
- Desired State – What You Define in Code:
- Defined in
.tffiles - Represents what you want your infrastructure to look like
- Example: “I want 2 EC2 instances with type t3.micro in us-east-1”
- Defined in
- Known State – What Terraform Remembers: [CALLED "Terraform State"]
- Stored in
terraform.tfstate - Represents what Terraform thinks is currently deployed in the cloud platform
- Includes resource IDs, IPs, tags, metadata, etc.
- Example: “Terraform created 2 EC2 instances last time and here are their IDs and IPs”
- Stored in
- Actual State – What Really Exists in the Cloud:
- The real, live infrastructure in your cloud account
- Could differ if someone made changes outside Terraform (manual edits or scripts)
- This is called Drift (Drift is NOT good)
Scenario 1: No State Exists – New Resource
- (Step 1) Known State in
terraform.tfstate:- No
.tfstatefile exists yet, so Terraform has no record of any resources - This means the Known State is empty
- No
- (Step 2) Define Desired State in Code:
- You define a new resource in code, such as an S3 bucket
- Example:
resource "aws_s3_bucket" "demo" { bucket = "my-first-bucket" } - This becomes the Desired State
- (Step 3) Plan: You run
terraform plan - (Step 3A) Compare Desired vs Known State:
- Terraform notices the S3 bucket is not present in the known state
- It marks the bucket for creation
- (Step 3B) Query the Actual State from Cloud Provider:
- Terraform checks with AWS to confirm whether the bucket already exists
- This is the Actual State, and it’s empty too (no such bucket exists)
- (Step 3C) Generate Execution Plan:
- Terraform compares: Desired ≠ Known AND Actual is empty
- It prepares a plan to create the S3 bucket
- (Step 4) Apply: You run
terraform apply - (Step 4A) Bucket Created:
- The bucket is created in AWS (Actual State Updated to Desired State)
- (Step 4B) Known State Updated:
- The
.tfstatefile is updated to record this new bucket in the Known State
- The
Scenario 2: Resource Updated in Code – Enabling Versioning
- (Step 1) Known State in
terraform.tfstate:- The
.tfstatefile shows that an S3 bucket named"my-first-bucket"exists with no versioning block - This represents the current Known State
- The
- (Step 2) Update Desired State in Code:
- You update the
.tffile to enable versioning on the S3 bucket:resource "aws_s3_bucket" "demo" { bucket = "my-first-bucket" versioning { enabled = true } } - This becomes the new Desired State
- You update the
- (Step 3) Plan: You run
terraform plan - (Step 3A) Compare Desired vs Known State:
- Terraform detects that versioning is now required (in Desired) but not present (in Known)
- It marks the bucket for update
- (Step 3B) Query the Actual State from Cloud Provider:
- Terraform queries AWS to get the live state of the bucket
- It confirms that versioning is not enabled
- (Step 3C) Generate Execution Plan:
- Terraform compares: Desired ≠ Known AND Known = Actual
- It prepares an update to enable versioning on the S3 bucket
- (Step 4) Apply: You run
terraform apply - (Step 4A) Bucket Updated:
- Terraform enables versioning on the S3 bucket in AWS
- The Actual State is now aligned with the Desired State
- (Step 4B) Known State Updated:
- The
.tfstatefile is updated to reflect that versioning is enabled - The new Known State now matches the Desired and Actual states
- The
Scenario 3: Manual Change in Console – Drift Detected
- (Step 1) Known State in
terraform.tfstate:- The
.tfstatefile shows that an S3 bucket named"my-first-bucket"exists withversioning = true - This is the Known State
- The
- (Step 2) Desired State in Code (Unchanged):
- Your
.tffile still expects versioning to be enabled:resource "aws_s3_bucket" "demo" { bucket = "my-first-bucket" versioning { enabled = true } } - This is the Desired State (same as last apply)
- Your
- (Step 3) Manual Change in Console:
- Someone disables versioning in the AWS Management Console
- Now the Actual State in the cloud is
versioning = false
- (Step 4) Plan: You run
terraform plan - (Step 4A) Compare Desired vs Known State:
- Terraform sees no change in code, so Desired = Known
- (Step 4B) Query the Actual State from Cloud Provider:
- Terraform refreshes the actual state by querying AWS
- It detects that versioning is not enabled anymore
- This is the Actual State, and it does not match Known
- (Step 4C) Detect Drift Between Known and Actual:
- Since the Known State has
versioning = truebut the Actual State isfalse - Terraform detects drift
- Since the Known State has
- (Step 4D) Generate Execution Plan:
- Desired = Known ≠ Actual
- Terraform prepares a plan to re-enable versioning to fix the drift
- (Step 5) Apply: You run
terraform apply - (Step 5A) Bucket Reconfigured:
- Terraform enables versioning again on the bucket in AWS
- The Actual State is corrected to match Desired and Known
- (Step 5B) Known State Reconfirmed:
.tfstateremains the same since versioning was already recorded as enabled- Drift is now resolved
What are the Options for Storing Terraform State? #
- Local Storage – ONLY for Beginners and Single Users:
- State file is stored on your local machine in the working directory
- Simple to set up, ideal for testing or solo use
- Not safe for teams — can lead to drift and conflicts (Developer A runs
terraform applyon their laptop and creates an EC2 instance, but Developer B doesn’t have the updated .tfstate file, so their next plan shows the EC2 instance as missing and may try to recreate it)
- Remote Backend for Terraform State:
- Amazon S3 Backend – Secure and Scalable for AWS Users: Stores state in an S3 bucket
- Azure Blob Storage: Ideal for Azure-Based Projects
- Google Cloud Storage: Best for Google Cloud Projects
- HCP Terraform(Terraform Cloud): Hosted State Management by HashiCorp
- Enables Team Collaboration: All team members and CI/CD tools work off the same central state
- Adds Backup and Audit Capabilities: Remote backends often support history and recovery options
# AWS S3 Remote Backend
terraform {
backend "s3" {
bucket = "my-terraform-state-bucket"
key = "path/to/my/terraform.tfstate"
region = "us-west-2"
dynamodb_table = "terraform-state-lock"
encrypt = true
}
}
# -------------------------------------
# Azure Storage Backend
# terraform {
# backend "azurerm" {
# resource_group_name = "terraform-state-rg"
# storage_account_name = "terraformstatestorage"
# container_name = "tfstate"
# key = "prod.terraform.tfstate"
# }
# }
# -------------------------------------
# Google Cloud Storage (GCS) Backend
# terraform {
# backend "gcs" {
# bucket = "my-terraform-state-bucket"
# prefix = "terraform/state"
# }
# }
# -------------------------------------
# HCP Terraform Backend
# terraform {
# cloud {
# organization = "my-organization"
# workspaces {
# name = "my-workspace"
# }
# }
# }
# -------------------------------------
# Consul Remote Backend
# terraform {
# backend "consul" {
# address = "consul.example.com:8500"
# scheme = "https"
# path = "terraform/myproject"
# }
# }
Practical Example: Remote Backend State Management + Locking #
- S3 Bucket for State Backend: Create an S3 bucket to store the Terraform state file remotely, enabling team collaboration and state persistence
- Versioning for State Bucket: Enable object versioning on the S3 bucket to support rollback and history of state file changes
- Encryption for State Bucket: Apply server-side encryption (AES256) to protect sensitive state data at rest
- DynamoDB for State Locking: Create a DynamoDB table to manage state locks and prevent simultaneous modifications during Terraform operations
# ---------------------------------------------
# ☁️ PROVIDER BLOCK
# WHAT: Configures AWS as the target platform
# WHY: Needed to provision S3, DynamoDB, IAM
provider "aws" {
region = "us-east-1"
}
# ---------------------------------------------
# 🗃️ STATE BACKEND BUCKET (S3)
# WHAT: Stores Terraform state file
# WHY: Enables collaboration, versioning, recovery
resource "aws_s3_bucket" "backend_state" {
bucket = "my-app-backend-state"
lifecycle {
prevent_destroy = true
# Prevents Terraform from destroying the resource
# when terraform destroy is run
# Prevent accidental deletion of state bucket
}
}
# ---------------------------------------------
# 🔄 VERSIONING FOR STATE BUCKET
# WHAT: Enables history of state changes
# WHY: Helps rollback or debug state
# HOW: Enables object versioning
resource "aws_s3_bucket_versioning" "state_versioning" {
bucket = aws_s3_bucket.backend_state.bucket
versioning_configuration {
status = "Enabled"
}
}
# ---------------------------------------------
# 🔐 ENCRYPTION FOR STATE BUCKET
# WHAT: Enables server-side encryption
# WHY: Protect sensitive state data at rest
resource "aws_s3_bucket_server_side_encryption_configuration"
"state_encryption" {
bucket = aws_s3_bucket.backend_state.bucket
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
# Advanced Encryption Standard with a 256-bit key
# Most secure and widely used symmetric encryption algorithm
}
}
}
# ---------------------------------------------
# 🔒 DYNAMODB TABLE FOR STATE LOCKING
# WHAT: Prevents multiple users modifying state simultaneously
# WHY: Avoids race conditions, corruption
resource "aws_dynamodb_table" "state_lock_table" {
name = "my-app-locks"
# You only pay for read/write units used
# Cost-effective and ideal for
# low-frequency operations like Terraform runs
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}
# ---------------------------------------------
# 🚀 REMOTE BACKEND CONFIGURATION (IN USERS MODULE)
# WHAT: Defines how Terraform connects to S3 state
# WHY: Enables collaboration and locking
# WHEN: Must be added to the root module
terraform {
backend "s3" {
bucket = "my-app-backend-state"
key = "my-app/backend-state"
region = "us-east-1"
dynamodb_table = "my-app-locks"
encrypt = true
}
}
# ---------------------------------------------
# 🙋♂️ IAM USER RESOURCE EXAMPLE
# WHAT: Creates an IAM user per environment
# WHY: Demonstrates use of terraform.workspace
# HOW: Workspace controls prefix (e.g., dev_...)
resource "aws_iam_user" "my_iam_user" {
name = "${terraform.workspace}_my_iam_user_abc"
}
# ---------------------------------------------
# 📤 OUTPUT BLOCK
# WHAT: Shows complete IAM user details
# WHY: Useful to inspect result after apply
output "my_iam_user_complete_details" {
value = aws_iam_user.my_iam_user
}
Remote Backend FAQ #
What is the Advantage of Remote Backend?
- Enable Safe Team Collaboration: Multiple team members can share and access the same Terraform state file without conflicts
- Support State Locking: Prevents concurrent
applyoperations by locking the state file during changes - Ensure Automatic Backups and Versioning: Maintain history of state changes for rollback, and recovery
- Secure State Storage with Encryption: Store sensitive infrastructure data securely
- Enable CI/CD and Automation: Remote backends allow pipelines and automation tools to access and update infrastructure consistently
- Reduce Risk of Accidental Deletion or Loss: No risk of losing the state file if there is a problem with a developer laptop
Why is Locking Needed?
- Prevents Concurrent Changes: Ensures that only one user or pipeline can modify the state at a time, avoiding conflicts and corruption
- Avoids Race Conditions: Stops multiple
terraform applyoperations from making overlapping or contradictory changes - Essential for Team Collaboration: Helps teams work safely on shared infrastructure without stepping on each other’s changes
🔐 How does Locking Work?
- Step 1: User 1 runs
terraform apply. Terraform tries to acquire a lock by writing a new item with a lock into the DynamoDB table - Step 2: If no existing lock is found, the write succeeds. User 1 successfully acquires the lock and begins modifying infrastructure
- Step 3: At the same time, User 2 also runs
terraform apply. Terraform checks for a lock in the DynamoDB table - Step 4: Terraform finds the existing lock (held by User 1). User 2 cannot proceed
- Step 5: User 1 completes the operation. Terraform automatically deletes the lock entry from the DynamoDB table
- Step 6: User 2 retries, finds the lock is now released, acquires the lock, and proceeds with their operation
- Step 7 (Optional): If a Terraform process crashes or is force-terminated, the lock remains in DynamoDB. A manual unlock using
terraform force-unlockis required to proceed
Scenarios with Terraform State #
-
Scenario: Can we use Git for State Management?
- Git is Not a State Store — It’s a Code Store: Use Git for managing your
.tfcode, not your.tfstatefile - (Disadvantage) Exposes Sensitive Data: State files often contain secrets, passwords, and tokens — committing them to Git risks data leaks
- (Disadvantage) No Support for Locking or Concurrency: Git can’t prevent two users from pushing conflicting state updates
- Git is Not a State Store — It’s a Code Store: Use Git for managing your
-
Scenario: What happens if you lose your Terraform state file?
- Terraform May Forget Everything It Created: Without the state file, Terraform no longer knows what resources it is managing — it may try to recreate everything
- Can Lead to Duplicate or Conflicting Resources: Running
terraform applywithout the state may provision new resources instead of updating existing ones - Orphaned Resources: Existing infrastructure becomes "orphaned" and must be managed manually or through other tools since Terraform no longer tracks it
- Best Practice: Always use remote backends with versioning and locking enabled, and back up state files regularly
-
Scenario: How can you recover/update a state file?
- Recover from
.tfstate.backupFile: Use the automatically created backup file in the local.terraform/directory (.tfstate.backupis an automatic backup of the previous terraform.tfstate file, created before each Terraform operation to help recover from accidental state corruption or loss) - Restore from Remote Backend Versioning: Use previous versions stored in remote backend (if versioning is enabled)
- Rebuild State Using
terraform import: Re-associate existing infrastructure with your Terraform code by importing resources manually (terraform import aws_instance.example i-0123456789abcdef0)- Note: Time consuming, error-prone and complex
- Use
terraform apply -refresh-onlyto Re-Sync Values: Reconnect to live infrastructure to refresh the values without making changes (only partial recovery for minor changes)- You have an EC2 instance managed by Terraform. Someone manually changed a tag on the instance. When you execute
terraform apply -refresh-only, Terraform updates the state file to reflect the current actual infrastructure (updated tag changes)
- You have an EC2 instance managed by Terraform. Someone manually changed a tag on the instance. When you execute
- Best Practices:
- Use remote backends with versioning and locking
- Always back up your state file regularly
- Recover from
How do you migrate a state file from a local backend to a remote backend? #
- Configure the Remote Backend: Update your Terraform configuration to specify the remote backend
- Initialize Terraform: Run
terraform init -migrate-state, Terraform will detect the backend change - State Migration Prompt: Terraform prompts whether you want to migrate the existing local state to the remote backend
- Confirm Migration: Confirm the migration, Terraform uploads the state to the remote backend and switches to using the remote state
- Verify Migration: Ensure state is correctly migrated by running
terraform planand confirming no unexpected changes
Example backend block migrating to S3:
- Update your Terraform configuration
# backend.tf - After preparing backend # Add remote backend configuration backend "s3" { bucket = "my-terraform-state-bucket" # Use actual bucket name key = "infrastructure/terraform.tfstate" region = "us-west-2" dynamodb_table = "terraform-state-locks" encrypt = true } - Run
terraform init -migrate-state$ terraform init -migrate-state Initializing the backend... Do you want to copy existing state to the new backend? Pre-existing state was found while migrating the previous "local" backend to the newly configured "s3" backend. No existing state was found in the newly configured "s3" backend. Do you want to copy this state to the new "s3" backend? Enter "yes" to copy and "no" to start with an empty state. Enter a value: yes Successfully configured the backend "s3"! Terraform will automatically use this backend unless the backend configuration changes.
What is the need for Data Source of Type Terraform Remote State? #
- Understanding Need to Share Outputs Across Terraform Projects: In large systems, one Terraform project may need values (like VPC IDs or bucket names) created by another — manually copying them leads to errors
- What is
terraform_remote_state: A data source used to read outputs from another Terraform project's remote state file - Enables Cross-Project Communication in Terraform: Helps connect multiple Terraform configurations without hardcoding values
- Share Outputs Like VPC IDs, Subnet IDs, or ARNs:
- One project creates infrastructure
- Another reads its outputs using
terraform_remote_state
- Read-Only Access to External State: Pulls only the outputs, not internal details or full resource metadata
- Keeps Projects Modular and Decoupled: Avoids monolithic Terraform code and makes configurations easier to manage
# 📥 DATA SOURCE BLOCK
# WHAT: Reads remote state from S3
# - Remote state file must exist already
# - The source project must define:
# output "vpc_id" { value = aws_vpc.main.id }
# - Helps organize large infra into modules/stages
data "terraform_remote_state" "network" {
backend = "s3"
config = {
bucket = "my-terraform-states"
key = "network/terraform.tfstate"
region = "us-east-1"
}
}
output "vpc_id" {
value = data.terraform_remote_state.network.outputs.vpc_id
description = "VPC ID from network stack"
}