Why do we need a Kubernetes Service? #
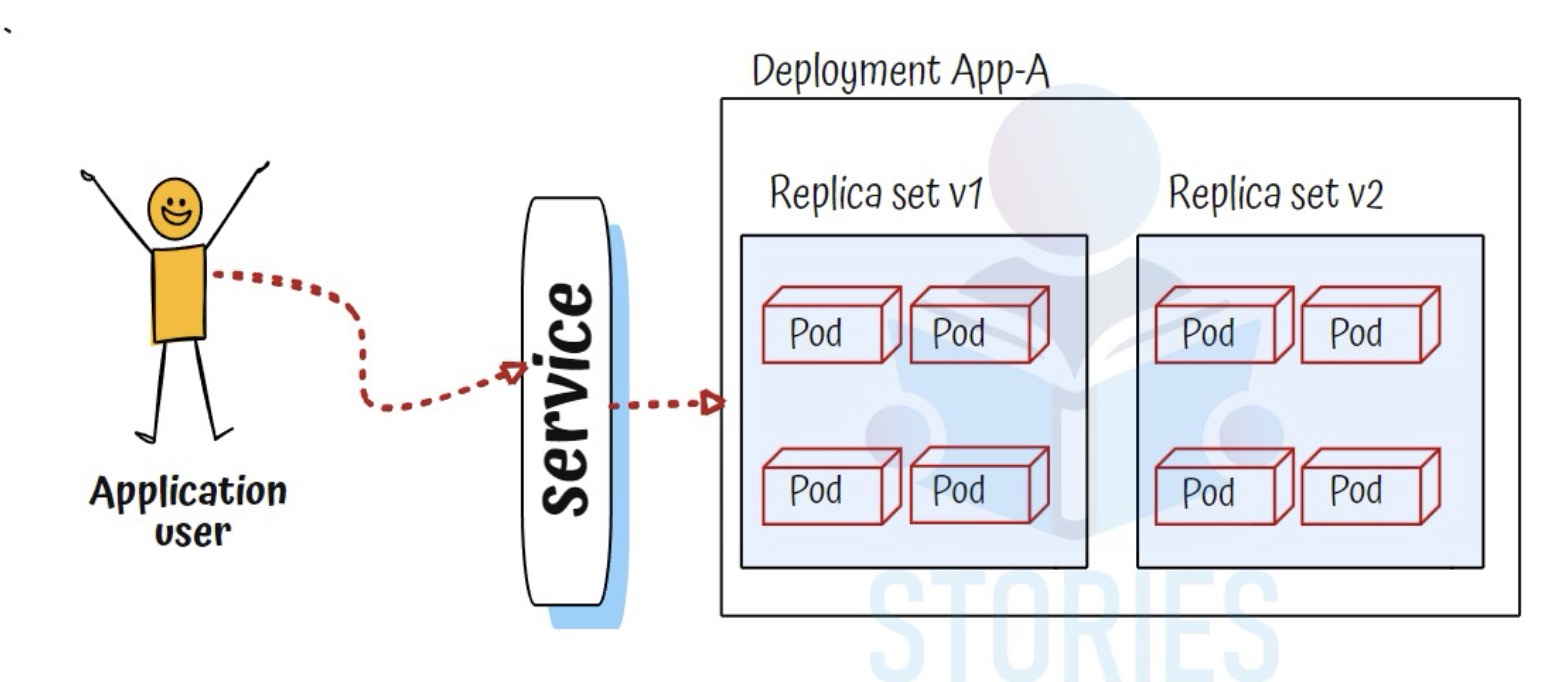
- Stable Networking: Provides a stable IP and DNS name for a set of Pods, abstracting their ephemeral nature
- Load Balancing: Distributes network traffic evenly across multiple Pods to ensure reliability and performance
kubectl expose deployment currency-exchange \
--type=LoadBalancerWhat are the different Types of Services? #
- ClusterIP
- Default Behavior: ClusterIP is the default service type in Kubernetes
- Internal Access Only: Exposes the service only within the cluster
- Used By Microservices: Ideal for internal communication between services
- No External Access: Not reachable from outside the cluster
- NodePort
- Port Binding: Exposes the service on a static port (30000–32767) on every node’s IP
- External Access via IP+Port: Accessible from outside via
http://<NodeIP>:<NodePort> - Dev/Test Friendly: Common in non-production environments for quick access
- Backed by ClusterIP: Uses a ClusterIP internally for routing to Pods
- LoadBalancer
- Cloud Integration: Requests a cloud load balancer from supported platforms (AWS, GCP, Azure)
- Public IP Assigned: Can make the service accessible via a public IP address
- Production Ready: Common in production setups where stable internet access is needed
- Uses NodePort + ClusterIP: Internally routes through NodePort to ClusterIP to reach Pods
Kubernetes Services Scenarios #
-
Scenario: Why should you not use a Pod IP Address to communicate with a microservice?
- Pods are Ephemeral (not permanent): They can be terminated and replaced at any time by the scheduler (e.g., due to failure or scaling down)
- New IP Address on Recreation: When a new Pod is created, it gets a new IP address
- Breaks Communication: Any microservice hardcoded to communicate with a specific Pod IP will break when that Pod is replaced
-
Scenario: I'm creating a Service of LoadBalancer type. But I do NOT see a Load Balancer being created.
- Local Limitation: Kubernetes distributions running locally—like Minikube, Docker Desktop, or kind—lack integration with cloud providers, so they cannot automatically provision external LoadBalancers (tool specific workarounds exist!)
- Cloud Dependency: In cloud environments, ensure that the Cloud Controller Manager is properly configured to provision and manage external LoadBalancers for
LoadBalancer-type Services.
-
Scenario: I'm unable to access a NodePort service via
http://<NodeIP>:<NodePort>- No Public Access: NodeIP might not be publicly accessible (especially in private cloud or local clusters)
- Firewall Blockage: Ports 30000–32767 might be blocked by firewalls or cloud security groups, preventing external access
- When does NodePort work?
- Same Network Access: If you're on the same network or subnet (e.g., your laptop and the cluster nodes are in the same corporate network or virtual private cloud), you can access the NodeIP directly
- Public IP Consideration: If the Kubernetes node has a public IP, it can be accessed over the internet
- Port Access Allowed: Access to NodePort is allowed by firewalls or cloud security groups
-
Scenario: I see another service type: ExternalName. What is it about? (This is different!)
- DNS Redirection: Used to map a Kubernetes service name to an external DNS (like
api.external.com) - Internal Access to External Services: Allows in-cluster Pods to access external services using a Kubernetes-style service name
- DNS Redirection: Used to map a Kubernetes service name to an external DNS (like
-
Scenario: Is a ClusterIP Created for NodePort or LoadBalancer?
- YES — Always Created: When you create a NodePort or LoadBalancer service, Kubernetes automatically creates a ClusterIP as the internal entry point for the service
- Core Routing Layer: The ClusterIP is the core routing layer; NodePort and LoadBalancer are simply access mechanisms layered on top
-
Scenario: How Does Traffic Flow to different types of Services?
- Inside the Cluster: Pods can use the ClusterIP directly for communication
- Outside the Cluster:
- NodePort: Exposes the service via
NodeIP:NodePort, which internally forwards traffic to the ClusterIP - LoadBalancer: Exposes the service via an external cloud load balancer, which routes traffic to the NodePort, then internally to the ClusterIP
- NodePort: Exposes the service via
What is the need for Fully Qualified Domain Name (FQDN)? #
- Precise Location: An FQDN specifies the precise location of a resource in the DNS hierarchy
- No Ambiguity: Avoids ambiguity by including all domain levels, from the specific host to the root
- General FQDN Structure:
<hostname>.<subdomain>.<domain>.<tld>. - Example:
login.api.example.com. - Ends with a Dot (
.)- Root Indicator: Denotes the root of the DNS tree
- Usually Omitted: Commonly omitted in day-to-day usage
- DNS Resolution
- DNS Usage: An FQDN is used by DNS to resolve the resource to its corresponding IP address
- Accurate Routing: Ensures accurate routing even across different namespaces, zones, or networks
- Example: FQDN in Kubernetes
- Format:
<service>.<namespace>.svc.cluster.local. - Example:
currency-exchange.default.svc.cluster.local. - Cluster-Wide Access: Used to access services across the cluster
- Format:
- Scenario: When to Use FQDN in Kubernetes?
- Configs: Configuring service endpoints in config maps or external scripts
How does a Service help with Service Discovery? #
-
Stable Way to Access Dynamic Pods
- Ephemeral Pods: Pods are ephemeral — they can restart, move to other nodes, and receive new IPs
- Stable Access Point: A Service provides a stable way to reach these changing Pods
-
Virtual IP (ClusterIP) and Load Balancing
- Virtual IP: A Service is assigned a ClusterIP — a virtual IP that does not change
- Traffic Distribution: Requests sent to this IP are load-balanced across all healthy Pods selected by the Service
-
DNS-Based Service Discovery
- Automatic DNS Setup: Kubernetes automatically sets up DNS entries for each Service
- Service FQDN Pattern: Kubernetes adds DNS records for every Service using the pattern:
<service>.<namespace>.svc.cluster.local - Name-Based Access: Any Pod can resolve and access other services using these DNS names — no need to hardcode IPs
-
Example: How Does a
currency-conversionmicroservice talk tocurrency-exchangemicroservice?- DNS Query Flow:
- Pod (of
currency-conversionmicroservice) issues DNS lookup (e.g.,currency-exchange.default.svc.cluster.local) - CoreDNS resolves the service name and returns the ClusterIP address of the service
- Pod (of
- Service Name Format: Pods can resolve services using different formats like:
currency-exchange(within the same namespace)currency-exchange.default(across namespaces)currency-exchange.default.svc.cluster.local(fully qualified domain name)
- DNS Query Flow:
Give a Practical Example of Service Discovery #
🅐 Deployment with Two Instances
- 🧱 Deployment Applied: A
Deploymentforcurrency-exchangeis created withreplicas: 2 - 📦 Pod Creation: A ReplicaSet with Two Pods (e.g.,
currency-exchange-abcde,currency-exchange-fghijwith individual IPs10.1.1.10,10.1.1.11) is created
🅑 ClusterIP Service Created
- 🛰️ ClusterIP Assigned: A
ClusterIPService namedcurrency-exchangeis created. It selects the Pods usingapp=currency-exchangeand gets a virtual IP, e.g.,10.96.0.10. - 📘 DNS Record Created: CoreDNS creates a DNS mapping for
currency-exchange.default.svc.cluster.localpointing to the ClusterIP - 🧩 Endpoints object Created: Kubernetes immediately creates an Endpoints object with the same name as the Service. The Endpoints Controller watches for Pods that match the Service’s label selector. The matching Pod IPs and ports are populated into the Endpoints object.
- ⚙️ iptables Rules Created:
kube-proxyon each node reads the Service and Endpoints, and sets up iptables rules to forward traffic from the ClusterIP to the IPs listed in the Endpoints object (i.e., to the 2 active Pods)
🅒 A New Instance is Created
- 📈 New Pod Created: The Deployment is scaled up, creating a new Pod (e.g.,
currency-exchange-xyz) with a new IP (e.g.,10.1.1.12) - 🧩 Endpoint Object Updated: Once the new Pod is Ready, it is automatically added to the Service’s Endpoints object
- 🔄 iptables Refreshed:
kube-proxydetects the change and updates iptables rules to include the new Pod IP for load balancing
🅓 An Instance is Removed
- 🧯 Pod Terminated or Scaled Down: One of the Pods (e.g.,
currency-exchange-fghij) is removed from the cluster - 🗑️ Endpoint Deregistration: As soon as the Pod enters Terminating or fails readiness, it is removed from the Endpoints object
- 🛡️ iptables Cleaned Up:
kube-proxyupdates the iptables rules to exclude the removed Pod IP, ensuring no traffic is sent to it
🅔 Request Using FQDN
- 🔍 DNS Resolution by Client: A client Pod issues a request to
http://currency-exchange.default.svc.cluster.local— CoreDNS resolves it to the ClusterIP (e.g.,10.96.0.10) - 📨 Traffic Sent to ClusterIP: The client sends a request to the ClusterIP
- 🚦 kube-proxy Load-Balancing: Based on the iptables rules (which reflect the current Endpoints), traffic is forwarded to one of the Ready Pod IPs
- ✅ Request Processed: The selected Pod handles the request and sends a response back to the client
CoreDNS
- Purpose: Provides DNS-based service discovery within the Kubernetes cluster
- How It Works:
- Watches the Kubernetes API Server for changes to Services
- Resolves FQDNs like
currency-exchange.default.svc.cluster.localto the Service's corresponding ClusterIP
Endpoints Object
- Purpose: Maintains a list of Pod IPs that are currently selected by the Service and are Ready to receive traffic
- Dynamic Updates: Endpoints Controller (a control-plane component) watches for Services, Matching Pods and automatically updates the Endpoints Object
- Used By:
kube-proxyuses the Endpoints object to configure iptables (or IPVS) rules, enabling traffic routing to healthy Pod IPs behind a Service
kube-proxy
- Purpose: Acts as the traffic director for Services on each node
- How It Works:
- Monitors the Kubernetes API for changes to Services and Endpoints
- Dynamically updates iptables (or IPVS) rules to route Service traffic to healthy Pods
- Ensures that traffic sent to a Service IP gets routed to one of the Ready Pods from the Endpoints object.
iptables
- Purpose: Store node-level routing rules to direct traffic from a ClusterIP (Service) to the correct Pod IPs
- How It Works: Rules are created and managed by
kube-proxy
Why do we need an Ingress? #
- Services: Multiple Microservices => Multiple Load Balancers: If each microservice is exposed externally using a Service of type
LoadBalancer, a separate load balancer is provisioned per microservice (especially in cloud environments) - Ingress: Multiple Microservices => One Load Balancer: Routes incoming HTTP(S) traffic to appropriate backend services
- Path-Based Routing: Forwards requests based on URL paths (e.g.,
/currency-exchange,/currency-conversion) - Host-Based Routing: Directs traffic based on hostnames (e.g.,
api.example.com,frontend.example.com)
- Path-Based Routing: Forwards requests based on URL paths (e.g.,
- Complete Example: Ingress > Service > Deployment (Needs currency-exchange and currency-conversion services of Type
ClusterIPorNodePort)- path: /currency-exchange pathType: Prefix backend: service: name: currency-exchange port: number: 80 - path: /currency-conversion pathType: Prefix backend: service: name: currency-conversion port: number: 80
Why do we need an Ingress Controller? #
- Ingress Is Only a Configuration
- No Execution Logic: An Ingress is a declarative object — it defines routing rules but doesn’t perform any routing
- Stored in etcd: Without a controller, the Ingress object simply sits in etcd and has no effect
- Ingress Controller Applies the Rules
- Monitors Ingress Resources: Continuously watches for changes to Ingress objects in the cluster
- Translates Rules: Converts Ingress definitions into actual configurations for tools like NGINX, HAProxy, or Envoy
- Programs Networking: Sets up the underlying networking (e.g., iptables or proxy routes) to route traffic to Services
- Without Ingress Controller
- No Traffic Routing: Ingress rules are not enforced, and external traffic cannot be routed
- No Load Balancing: Advanced features like path-based routing won’t work
- Popular Ingress Controllers
- NGINX Ingress Controller (most widely used)
- HAProxy
- Traefik
- Kong
- AWS ALB Ingress Controller (for Amazon EKS)
- Create Your Own: Custom controllers can be written to suit specific needs
Compare: Ingress vs LoadBalancer Service #
| Feature | Ingress | LoadBalancer Service |
|---|---|---|
| Purpose | Acts as an HTTP/HTTPS router for multiple Services | Exposes a single Service externally |
| Scope | Can route to many Services based on host/path | Tied to one Service only |
| Controller | Ingress Controller (e.g., NGINX, Traefik) | Cloud Controller Manager (provisions cloud load balancer). LoadBalancer Services rely on the cloud provider’s infrastructure (e.g., AWS ELB, Azure Load Balancer). |
| External IP | Shared across all routes via Ingress controller | Each Service gets a separate external IP |
| Routing Rules | Path-based, host-based | No routing; forwards all traffic to one backend |
| Best For | Web applications, microservices behind shared entrypoint | Exposing a standalone API, database, or service directly |