Why Asynchronous Communication? #
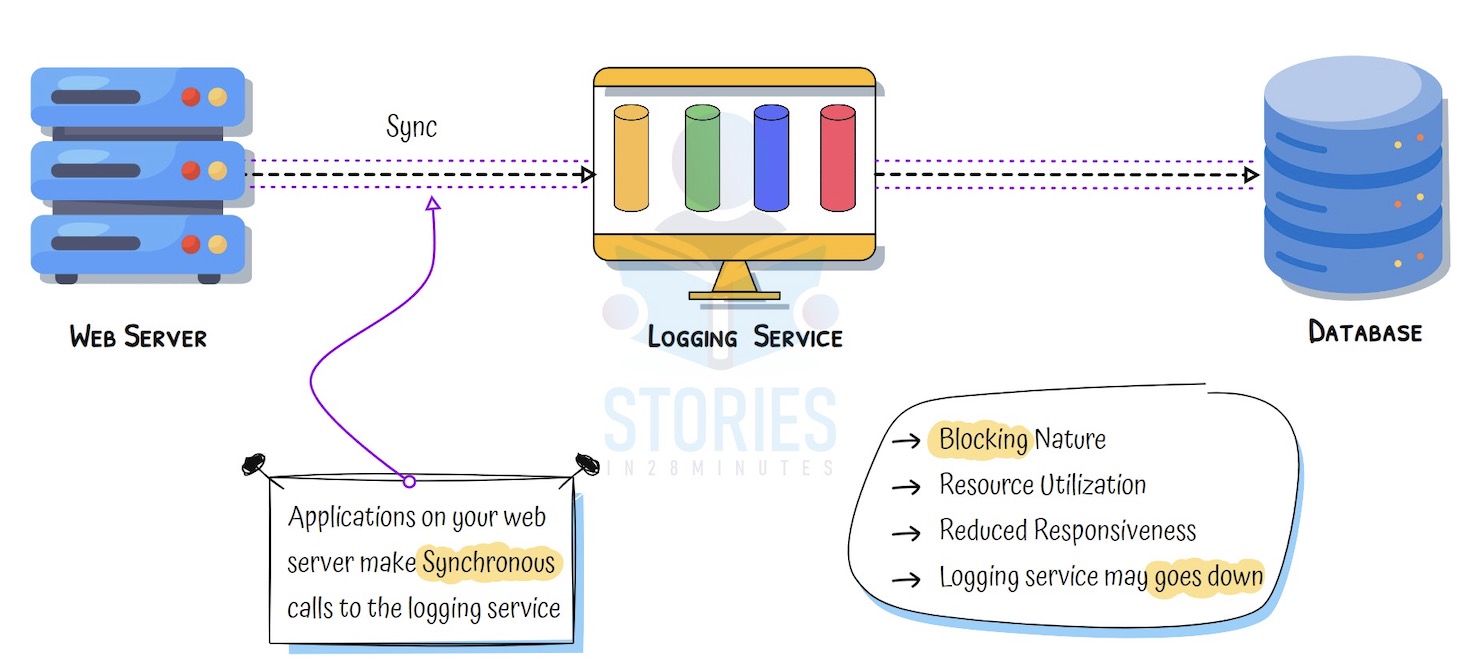
Synchronous Communication – Example
- Scenario: A web app calls a logging service to store logs for every user action
- Tight Coupling: The web app waits for the logging service to respond before continuing
- Failure Risk: If the logging service is slow or crashes, the user request may fail or be delayed
- Latency Impact: Every dependency adds to response time, affecting user experience
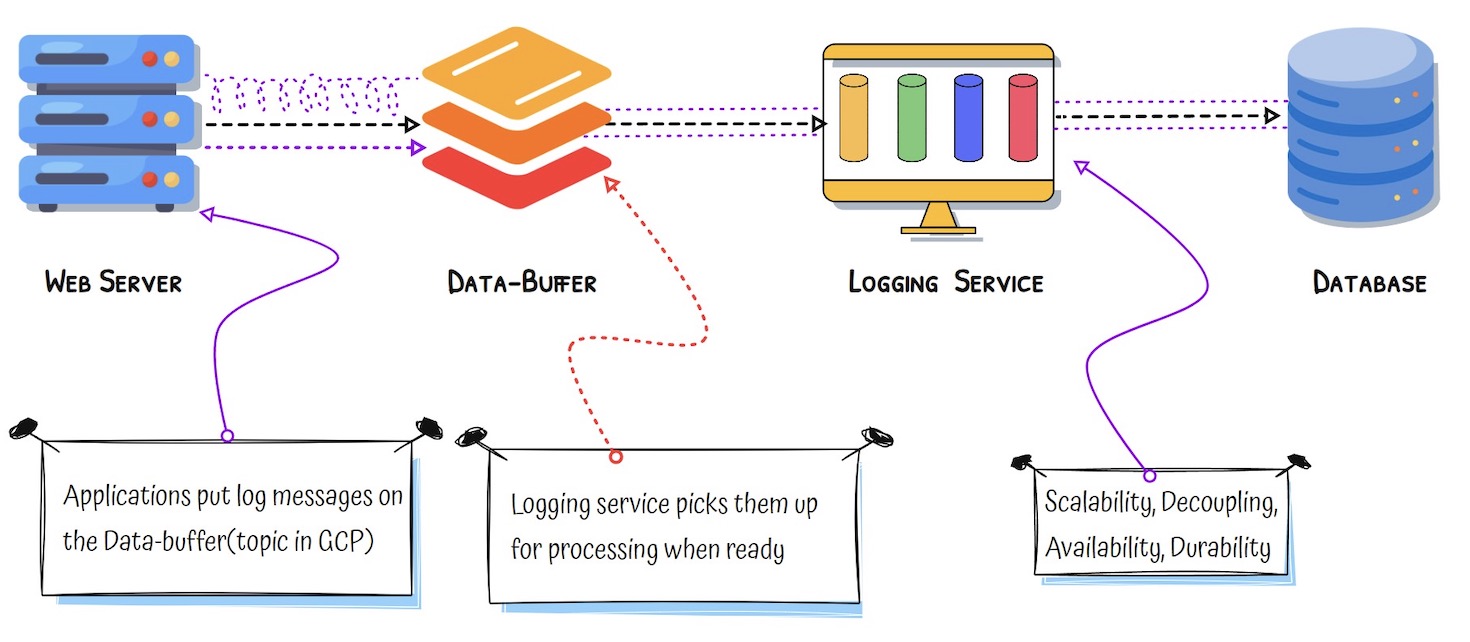
Asynchronous Communication – Decoupled Systems
- What is Changed?: The web app sends logs to a message queue instead of the logging service directly
- Queue in the Middle: Messages are safely stored and processed later
- Loose Coupling: The app does not need to wait — it moves on instantly
- Resilience: If the logging service is down, messages are still stored and processed later
- Traffic Spikes Handled Gracefully: Queue absorbs spikes; services can catch up later
Synchronous vs Asynchronous Communication
| Synchronous | Asynchronous |
|---|---|
| Tight coupling between systems | Loose coupling via queues or events |
| Fails if downstream service fails | Continues working even if downstream is slow or down |
| Harder to scale during spikes | Easier to scale each part independently |
| Real-time but fragile | More resilient and scalable |
| Use when real-time response is essential – e.g., payment confirmation, authentication, .. | Use when the system can continue without waiting for the task to complete — like sending emails, writing logs, or queuing background jobs |
Patterns in Asynchronous Communication
Note: These patterns are not mutually exclusive. A system might use an event bus to trigger a workflow, which pulls from a queue and publishes updates via pub/sub.
| Pattern | Description & Example |
|---|---|
| Queue-based Messaging | Temporarily hold messages in a queue so systems can process them later. Useful when producers and consumers work at different speeds. Example: A order system places orders in a queue, and a delivery service picks them up one by one. |
| Publish/Subscribe | Send a message to many systems at once. One sender, many receivers. Great for real-time notifications or updates. Example: A user uploads a photo, and it triggers image processing, thumbnail creation, and an audit log—all at the same time. |
| Streaming Data | Process real-time flows of data continuously. Ideal for analytics, logs, or metrics coming in non-stop. Example: A stock trading app processes live trade data as it's generated. |
| Event Bus | Configure event sources and event destinations. Routes events from sources to destinations based on your configuration. Example: When a file is uploaded, route the event to a function for processing. |
| Workflow Orchestration | Coordinate a series of steps in a process, with logic and decisions. Useful for long-running or multi-step operations. Example: An onboarding workflow that verifies documents, sends a welcome email, and creates user records step by step. |
What is Queue-based Messaging (Pull)? #
Why Queue-based Messaging?
- Scenario: Imagine an online store that takes orders quickly, but the delivery system processes them slowly — both work at different speeds
- Queue-based Messaging: A temporary holding system where messages (like orders) wait until the next system is ready to process them. Helps decouple services and smooth out spikes in traffic.
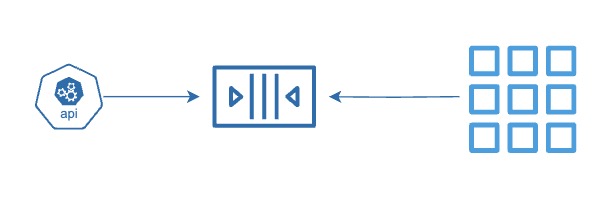
Step By Step
- Step 01: Create a message queue to temporarily store messages between systems that don’t run at the same speed
- Step 02: A producer sends a message to the queue — for example, placing an order or uploading a task
- Step 03: The message is safely stored in the queue until the consumer is ready — this avoids dropping messages during high load
- Step 04: A consumer reads the message from the queue when it is ready — one at a time or in batches
- Step 05: After processing, the consumer can delete the message from the queue to prevent duplicate work
- Step 06: If the consumer fails to process the message, it stays in the queue or is moved to a dead-letter queue for review
- Step 07: Multiple consumers can be added to scale processing without changing the producer
- Reliable and Decoupled: The producer and consumer do not need to run at the same time — the queue makes the system more resilient and scalable
Key Benefits
- Decoupled Systems: No need to run at the same time
- Pull-Based: Consumers read messages when ready
- Reliable Delivery: Messages are stored safely
- Scalable: Scale producers and consumers separately
- Error Handling: Use retries and dead letter queues for failures
| Queue Service | Provider |
|---|---|
| Amazon SQS | AWS |
| Azure Queue Storage | Azure |
| Google Cloud Pub/Sub (Pull) | Google Cloud |
What is Publish Subscribe Messaging (Push)? #
Why Publish/Subscribe?
- Scenario: Imagine a photo-sharing app where uploading a photo should notify multiple services — one for resizing, one for tagging, one for storing metadata
- Publish/Subscribe: A messaging pattern where one event is sent to multiple subscribers at the same time. Each system gets its own copy and processes it independently
- Goal: Notify multiple systems at once
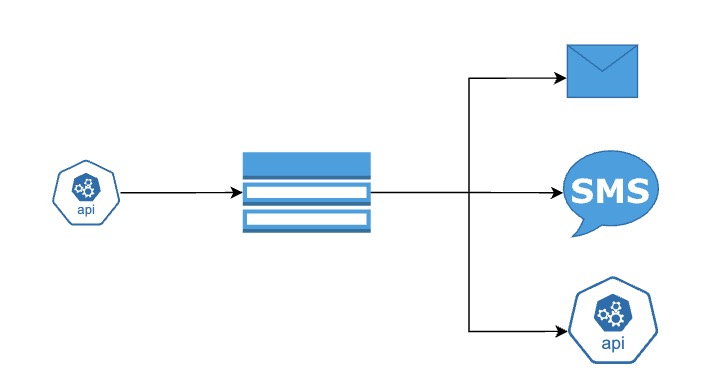
Step By Step
- Step 01: Create a topic to act as a central channel where messages will be published
- Step 02: One or more subscribers register their interest in receiving messages from this topic
- Step 03: A publisher sends a message to the topic — for example, a new user signs up or a file is uploaded
- Step 04: The topic immediately forwards the message to all subscribers — this is a push-based system
- Step 05: Each subscriber gets a separate copy of the message and can handle it independently
- Step 06: Subscribers can be of different types — webhooks, email, SMS, queues, or even functions
- Step 07: If a subscriber is temporarily unavailable, the system may retry or store the message depending on the setup
Key Benefits
- Fan-Out: One message, many receivers
- Push-Based: Delivered instantly — no polling
- Loosely Coupled: Publisher doesn’t know subscribers
- Flexible Targets: Works with queues, APIs, emails, and more
- Great for Notifications: Trigger multiple actions in parallel
| Cloud Service | Provider | Example Use Case |
|---|---|---|
| Amazon SNS | AWS | Send real-time notifications to multiple services after file upload |
| Azure Event Grid | Azure | Notify multiple subscribers when a blob is added to storage |
| Google Cloud Pub/Sub | Google Cloud | Fan-out messages to multiple microservices |
What is the need for Streaming Data? #
Why Streaming Data?
- Scenario: Imagine a website where users click links, watch videos, and interact every second. You want to track all of it in real time for analytics or alerts
- Streaming Data: Data that arrives continuously in small chunks, usually with a timestamp
- Goal: Process data instantly as it arrives
- Example: Track user clicks on a website in real time
Step By Step
- Step 01: Set up a streaming service that can collect and process data in real time — one event at a time
- Step 02: A producer (like a mobile app, sensor, or server) continuously sends data to the stream — such as logs, clicks, or metrics
- Step 03: The streaming platform partitions the data and stores it temporarily for processing
- Step 04: One or more stream processors read from the stream, often in real time or near real time
- Step 05: The processor may clean, transform, filter, or enrich the data before passing it on
- Step 06: The processed data can be sent to multiple destinations — like dashboards, storage, or alerts
- Step 07: The system keeps moving — new data keeps flowing in, and the pipeline keeps processing without pause
Key Benefits
- Real-Time Input: Handles logs, metrics, clicks as they happen
- Ordered & Timestamped: Events come in sequence with time info
- Instant Processing: Power dashboards, alerts, fraud detection
- Scalable: Stream split into partitions for parallel processing
| Cloud Service | Provider | Example Use Case |
|---|---|---|
| Amazon Kinesis Data Streams | AWS | Real-time clickstream analytics for a website |
| Azure Event Hubs | Azure | Ingest and process IoT sensor data in real time |
| Google Cloud Pub/Sub (Streaming) | Google Cloud | Stream transactions for fraud detection |
| Amazon MSK / Azure Kafka / Google Cloud Kafka | All | Log stream processing using managed Apache Kafka |
Why do we need an Event Bus? #
What Are Cloud Service Events?
- Definition: Notifications automatically generated by cloud services when something happens (e.g., file uploaded, resource deleted)
- Goal: Automate reactions to changes in your cloud environment
- Examples:
- Object added to a storage bucket
- New VM instance created
- API Gateway receives a request
- Database row updated
Common Use Cases
- Storage: Process or scan files after upload
- Security: Alert when IAM policies change
- Automation: Start pipelines when code is committed
- Compliance: Log and archive data when resources are modified
Why do we need an Event Bus?
- Scenario: You need to process a Cloud Service Event. Imagine a virtual machine (VM) is stopped — and you want to automatically trigger a serverless function to send an alert, log the event, or clean up temporary resources.
- Event Bus: You can register the VM service as the event source, and the serverless function as the target. When the VM is stopped, the event bus detects the event and automatically routes it to the function — without writing any polling logic or custom glue code.
- Centralized Routing: Event Bus works with cloud service events, partner events, and custom events from your own applications — all routed through a central system that applies rules to determine where each event should go
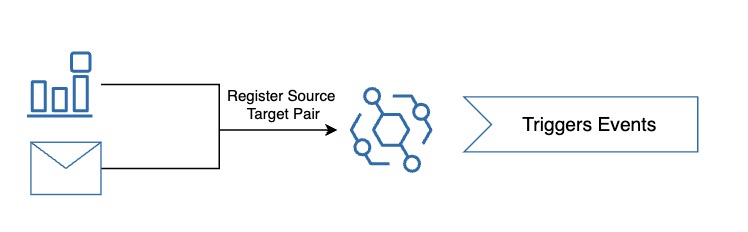
Step By Step
- Step 01: Set up an event-driven system that reacts to cloud resource changes — like file uploads to storage
- Step 02: Define an event source (e.g., an object storage bucket) and configure a target (e.g., serverless function, queue, or notification) that should handle the event
- Step 03: A user or system uploads a file to the storage bucket — this is the event trigger
- Step 04: The cloud platform automatically detects the event and forwards it to the configured target — no need to poll or check manually
- Step 05: The target processes the event — for example, a function resizes an image, extracts metadata, or sends an alert
- Step 06: The system can apply filters to trigger only when certain conditions are met
- Step 07: This works reliably and scales automatically — even if thousands of events occur per second
- Responsive and Serverless: Events trigger logic immediately, enabling real-time automation without managing infrastructure
Key Things to Know
- Trigger-Based Logic: Target is invoked in the event happens
- Real-Time Response: No polling or delay — events are captured and acted on instantly
- Flexible Targets: Events can trigger functions, queues, or workflows
- Filterable Events: Process only the events that matter using rules or filters
Supported in Different Cloud Platforms
| Cloud Service | Provider | Example Use Case |
|---|---|---|
| Amazon EventBridge | AWS | Trigger Lambda when a file is uploaded to S3 |
| Azure Event Grid | Azure | Automatically start logic app on resource change |
| Google Eventarc | Google Cloud | Trigger Cloud Run when Firestore data changes |
Why CloudEvents?
- Scenario: Imagine integrating events from different systems — each has a different format, causing confusion and complex code
- CloudEvents: A standard format for describing event data, making it easier to build event-driven systems across platforms
- Created by: CNCF (Cloud Native Computing Foundation)
- Goal: Solve the challenge of inconsistent event formats from different publishers
Key Advantages
- Consistency: Same format for all events — easier to read, parse, and debug
- Tooling Support: Use common libraries across clouds and languages (Java, Python, Go, etc.)
- Portability: Events can move between AWS, Azure, Google Cloud, or on-premises without rewriting code
- Interoperability: Producers and consumers can work independently
Cloud Managed Event Bus Services support CloudEvents
- AWS: Amazon EventBridge (supports CloudEvents format)
- Azure: Azure Event Grid (native support for CloudEvents v1.0)
- Google Cloud: Eventarc (uses CloudEvents as standard format)
What is the need for Workflow Orchestration? #
Why Workflow Orchestration?
- Scenario: Imagine onboarding a new employee — it involves multiple steps like verifying documents, creating accounts, and sending welcome emails
- Workflow Orchestration: A system that coordinates all steps in the right order with logic, retries, and decision-making — and tracks the status from start to finish
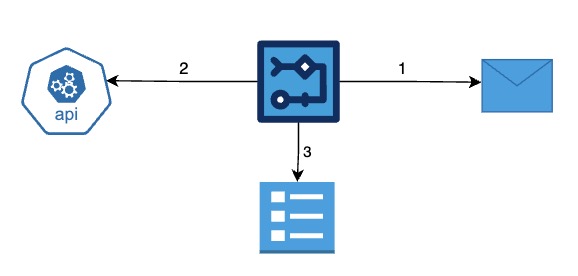
Step By Step
- Step 01: Define a workflow made up of multiple steps — each step performs a task like calling an API, running a function, or waiting for approval
- Step 02: Add decision logic — like if/else, retries, timeouts — to control the flow based on conditions or failures
- Step 03: Trigger the workflow from an event (such as a new order or new employee is created) or configure a schedule
- Step 04: The orchestrator ensures steps run in the right order, handles failures, and resumes from where it left off if needed
- Step 05: You can monitor, pause, or restart workflows
- Reliable and Visual: Automate multi-step processes across systems — with full visibility and no manual coordination
Key Things to Know
- Step-by-Step Automation: Coordinates tasks in a defined sequence
- Built-in Logic: Supports conditions, retries, and timeouts between steps
- State Tracking: Keeps track of which step succeeded or failed
- Works Across Systems: Connects APIs, functions, databases, and external systems
- Visual and Monitorable: Provides dashboards to monitor, audit, and debug workflows easily
Workflow Orchestration
| Cloud Service | Provider | Example Use Case |
|---|---|---|
| AWS Step Functions | AWS | Multi-step order processing with validation and notification |
| Azure Logic Apps | Azure | Automate HR onboarding process with email and approval steps |
| Durable Functions | Azure | Serverless orchestration with retries and parallel steps |
| Google Workflows | Google Cloud | Sequence Cloud Functions to process uploaded files and move data |